Adapting HPX’s Parallel Algorithms for Usage with Senders and Receivers

- What is
partitioner_with_cleanupin HPX - What are Senders and Receivers
- What is this project about
- Difficulties and challenges
- Completed works
- Future works
- Acknowledgments
This report presents the final outcomes of my Google Summer of Code 2025 project with the Ste||ar Group and serves as complete documentation for anyone interested in the implementation details and results.
HPX provides a comprehensive implementation of parallel algorithms that serves as both a standards-compliant C++ library and a high-performance computing runtime system. With the upcoming C++26 standard introducing the Senders/Receivers (S/R) programming model for asynchronous execution, it becomes crucial to ensure HPX’s compatibility with it.
However, parallel algorithms based on the partitioner_with_cleanup component, which is used for task partitioning and resource cleanup, currently don’t have support for the S/R model, this project aims to bridge the gap by adding modification to this component, adjusting these algorithms themselves and providing comprehensive unit tests.
What is partitioner_with_cleanup in HPX
The hpx::parallel::util::partitioner_with_cleanup component in HPX library serves as the central execution engine for HPX’s parallel algorithms, the functionality of it is mostly the same as hpx::parallel::util::partitioner, but introduces extra cleanup semantic. This critical infrastructure component handles the complex task of dividing work into parallel chunks, managing their execution across different policies, and ensuring robust error handling and resource cleanup.
To be specific, the running process of partitioner_with_cleanup can be divided into the following steps:
- Bind policy/executor parameters.
- Build partition shape and bulk-launch chunk work (
f1) on executor. - Reduce results (
f2) while applying error handling. - On any failure, run cleanup on successful chunks to roll back.
- Return result type dictated by policy
Within the partitioner_with_cleanup component, HPX provides two distinct implementations to handle different execution models. The static_partitioner_with_cleanup is used for non-task execution policies, including sequenced/parallel policies and S/R execution. In contrast, the task_static_partitioner_with_cleanup is used for task-based execution policies such as sequenced_task and parallel_task.
In the call chain, there are two main functions, which are the call function and reduce function, they are responsible for the partitioning and reducing process respectively.
The call function takes the following parameters: an execution policy policy, a range (a forward iterator first and a std::size_t value count), a per-chunk worker f1, a final reducer f2, and a cleanup function cleanup. This function firstly partitions the range into chunks according to the execution policy, calling f1 on all chunks, then call the reduce function to merge the algorithm results.
|
|
The reduce function takes three parameters: a list of chunk results workitems, a reducing function f, and a cleanup function cleanup, This function firstly waits for all workitems to complete. If there is any exception returned by workitems, the cleanup function will be called on all successful results and the captured exceptions are thrown again. If all the workitems are successful, a result of calling the reduce function will be returned.
|
|
The following is an image that illustrates its workflow.
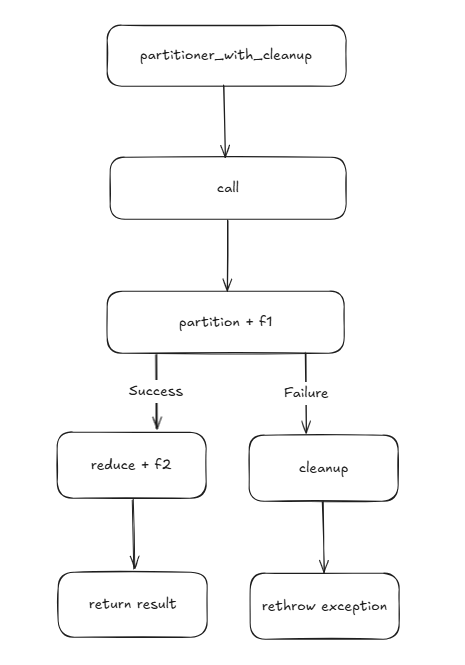
If you are interested in more details about HPX’s parallel algorithms, a good reference is Tobias Wukovitsch’s project of Google Summer of Code 2024, which includes a clear and detailed introduction.
What are Senders and Receivers
Since this project is about S/R, it’s important to provide a brief introduction to it.
Modern C++ has long lacked a standard way to express asynchronous operations. Existing approaches such as futures, callbacks, or third-party libraries often suffer from inconsistent semantics or limited support for cancellation and error handling, which may cause potential issues.
Hence, the C++ standards committee has been working on a proposal known as P2300: std::execution, which introduces a new abstraction for asynchronous programming called the S/R model. This proposal is expected to form the foundation of future concurrency support in the C++ standard.
At its core, the S/R model separates two roles: the Sender, which produces an asynchronous result, and the Receiver, which consumes it. A sender does not run work immediately but describes what will be done once execution starts.
To execute a sender, it should be firstly connected to a receiver through connect(), which forms an operation state, this object knows what to do and where the result should be given to. Then, start() must be called on it to trigger the actual asynchronous execution.
When the work completes, the sender signals the receiver in one of three ways:
- Value → the operation completed successfully and produced a result
- Error → the operation failed and communicates the failure downstream
- Stopped → the operation was cancelled before producing a result
This tri-state completion model makes error handling and cancellation first-class citizens rather than afterthoughts. It also allows asynchronous operations to be composed in a consistent and declarative style.
In the exact codebase, developers often uses functions like sync_wait(), when_all(), and let_value() to implicitly complete the connect() and start() operations. Here is a simple example:
|
|
What is this project about
The primary goal of this project is to extend HPX’s parallel algorithms so that they fully support the S/R model when built on top of the partitioner_with_cleanup component. The work is organized into three parts:
-
Extending
partitioner_with_cleanup
Introduce logic branches to handle calls originating from S/R-based execution, covering both launch policies and execution policies. These adaptations ensure clean integration with the S/R model while preserving existing semantics. -
Adapting algorithm implementations
Modify affected algorithms to align with S/R usage. To be specific, changing the return type fromalgorithm_resulttodecltype(auto)so that senders are correctly deduced as return values. Additionally, disable early exits in the S/R branch to keep sender chains intact and faithfully represent the asynchronous workflow. -
Developing unit tests
Provide a comprehensive suite of tests for the affected algorithms. Each test evaluates four combinations of launch and execution policies:hpx::launch::syncwithseq(task)hpx::launch::syncwithunseq(task)hpx::launch::asyncwithseq(task)hpx::launch::asyncwithunseq(task)
These combinations cover major usage scenarios and mirror test patterns used elsewhere in HPX, ensuring consistency and reliability.
Difficulties and challenges
The key challenge of this project is how to modify the partitioner_with_cleanup component so that it can handle failures gracefully. While the regular partitioner component can assume everything will work perfectly and simply return the reduced results, partitioner_with_cleanup must be more cautious. It needs to track which subtasks succeed or fail, and more importantly, it must call cleanup functions for successful work when other parts of the operation fail.
As mentioned above, an asynchronous operation executed in the S/R model can finish in three distinct ways, which are Value, Error, and Stopped. Therefore, if any chunk fails, the partitioning function call completes on the error channel. Consequently, the reduce function can only observe an error signal rather than all the chunk results from the algorithm, making it impossible to identify which chunks completed successfully and preventing proper cleanup function from being called.
Therefore, we need to distinguish between normal results and errors during execution. To achieve this, the call function wraps the original algorithm parameter f1 in a lambda expression, ensuring that every return value is stored in a variant type. Each partition task therefore produces either a normal Result or an exception_ptr.
Next, the reduce function linearly traverses all partition results. If it detects an error, it first releases the resources held by already successful subtasks, and then rethrows the exception.
This pseudocode illustrates the principle, actual implementation differs in template details.
|
|
In this way, although each subtask passes its result by value, the final Sender always completes in a successful state by returning a container of variants. The caller can then inspect this container to uniformly detect errors, perform cleanup, and rethrow exceptions if necessary.
Completed works
This project successfully integrated S/R model support into all parallel algorithms that utilize the partitioner_with_cleanup component, accompanied by comprehensive unit test coverage.
Memory Construction Algorithms:
uninitialized_copy,uninitialized_copy_nuninitialized_default_construct,uninitialized_default_construct_nuninitialized_fill,uninitialized_fill_nuninitialized_value_construct,uninitialized_value_construct_n
Memory Movement Algorithms:
uninitialized_move,uninitialized_move_nuninitialized_relocate,uninitialized_relocate_backward,uninitialized_relocate_n
All implementation details, code modifications, and test cases can be reviewed in PR #6741, which contains the complete set of changes of project.
Future Work
This project implements a solid extension for S/R model integration in HPX, with the following development priorities:
The immediate focus should be completing algorithm coverage by adapting remaining parallel algorithms to the S/R model. Current progress and remaining work items are tracked in this table.
Next, development should shift toward performance optimization through comprehensive benchmarking and advanced S/R composition patterns to minimize overhead and maximize efficiency.
Acknowledgments
I would like to express my sincere gratitude to Hartmut Kaiser, Isidoros Tsaousis-Seiras and Panos Syskakis for their invaluable guidance and continuous support throughout this project. Their expertise was instrumental in helping me navigate complex technical challenges.
I’m also grateful to Tobias Wukovitsch for his excellent work and report in Google Summer of Code 2024, which provided essential background for this work.
Finally, I thank Google and the Google Summer of Code program for providing this incredible opportunity to contribute to open-source software and grow as a developer.